ODC를 구축한 기술 - Serverless, SPA, AWS Lambda Edge
https://blog.roto.codes/odc-tech-stack/ 에서 이어지는 글.
ODC Front-end는 이전 글에서 이야기했던 대로 SPA 구조로 되어있으면서 별도의 서버 애플리케이션 없이 운영 중에 있다. 전형적인 serverless 형태인데 Create React App을 이용해 개발된 SPA 웹 애플리케이션을 빌드하고, 빌드 후에 생성되는 정적인 파일들(html, js, css, image 등)을 s3에 업로드 한 다음 해당 s3를 cloudfront를 통해 서비스 하는 형태이다.
cloudfront와 S3
amazon s3 그리고 amazon cloudfront 가 핵심이다.
그림으로 보면 다음과 같다.
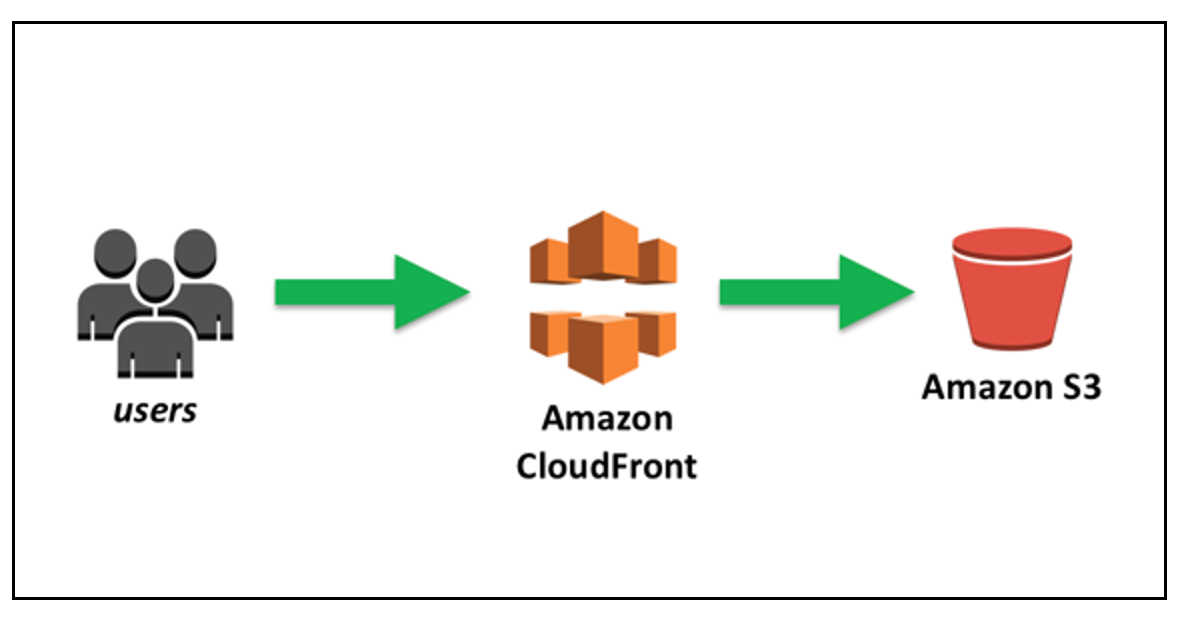
(이미지 출처: https://aws.amazon.com/ko/blogs/korea/amazon-s3-amazon-cloudfront-a-match-made-in-the-cloud/)
이렇게 하면 다음과 같은 장점들이 있다.
- 트래픽이 과다하게 몰려도 Front-end쪽은 서버 증설에 대한 리스크를 지지 않는다. 별도의 애플리케이션 서버가 없기 때문이다.
- 만약 node + express나 django 상에서 Front-end를 제공했다면, 트래픽에 비례해서 서버 인스턴스를 늘리는 등의 조치를 취해야 했을 것이다.
cloudfront자체가 Global CDN 역할을 해준다.- Edge Location 설정을 통해 실제 서비스에 접속하는 네트워크망에서 가까운 서버에서 자원을 얻게 할 수 있다. 미국에서 접속하는 요청이면 미국 CDN에서, 한국에서 접속하는 요청이면 한국 CDN에서 정적 자원들을 가져온다.
- 빌드와 배포가 매우 간편해진다.
- 환경에 맞게 빌드 후 생성된 파일들을
- s3에 업로드(sync를 사용하였다)
- 연결된 cloudfront의 cache invalid
- 위의 두 스텝으로 배포가 끝나버린다.
- 이 덕분에
Front-end의 배포 부담이 매우 줄어든다. - 또한 단순히 cdn에 배포하는 개념이기 때문에, API의 변경으로 break change가 있지만 않다면 front-end 배포 진행 중에 접속 중인 사용자가 에러를 볼 확률도 적다.
- 환경에 맞게 빌드 후 생성된 파일들을
위의 개념은 firebase에서는 https://firebase.google.com/docs/hosting 을 이용하면 비슷한 효과를 낼 수 있다.
SPA의 장점
그외에도 SPA(Single Page Application)으로 만들어지면 다음과 같은 장점들이 있다.
웹 보다는 앱에 가까운 사용성을 얻을 수 있다.
- 초기 접속 시 필요한 자원들을 미리 얻어놓고 페이지 이동 시 클라이언트에서 바뀌는 영역의 렌더링만 다시 하는 것이기 때문에 반응이 애플리케이션처럼 즉각적이다.
- 연속적인 처리가 필요한 페이지들의 구현이 용이하다.(회원가입 step 등)
hot loader 등의 도구로 빠른 개발과 디버깅이 가능하다.
- 코드의 수정이 실시간으로 반영되는 도구들의 등장으로 인해 코드 수정에 대한 빠른 피드백이 가능하다.
- 로컬 서버에 배포를 하거나 재기동하는 등의 시간을 아낄 수 있다
- 이거 생각보다 괴롭다.
API와 병렬로 개발을 진행할 수 있다.
- API에 대한 응답 Spec만 잘 협의해두면, API를 아직 개발 중인 상태더라도 병렬로 개발을 진행할 수 있다.
- 이로 인해 커뮤니케이션이 상당히 중요하다.
- TypeScript 등으로 API 응답 타입을 정의 해놓고 개발하면 나중에 응답 Spec이 변경되어도 기민하게 대응이 가능하다.
- 협의해둔 API를 http://mockable.io/ 과 같은 서비스를 통해 서빙하고 이를 이용해 구현하면 나중에 API 배포 후 end point만 갈아끼우면 된다.
이외에도 많은 장점들이 있지만, 눈에 띄는 장점은 이정도가 아닐까 싶다.
물론 장점이 확실한 만큼 단점들도 확실하다.
SPA의 단점
크롤링 문제
- 하나의
index.html만 존재하고 url 패턴에 따라 동적으로 화면에 클라이언트 사이드에서 렌더링하는 방식이기 때문에, 크롤러 등이 내용을 긁어갈 때 매번 같은 내용(하나만 존재하는 index.html)을 긁어갈 수 밖에 없다.- 구글봇 같은 경우 SPA 애플리케이션이면 클라이언트에서 렌더링된 이후의 내용을 긁어갈 정도로 똑똑하지만, facebook이나 카카오톡 등에서 공유할 때 긁어가는 meta tag는 서버에서 url을 요청하고 응답이 온 순간의 head를 긁어가기 때문에 index.html에 고정된 내용만 긁어가게 된다.
거대해지는 번들
- create-react-app의 경우 기본적으로
webpack으로 코드를 하나로 만든다.- 이는 애플리케이션 첫 접속 시 로딩 시간이 길어지는 문제를 갖게 되며
- 자바스크립트 용량이 너무 커서 자바스크립트 초기 로딩에 시간을 많이 소모하기에 Time to Interactive 수치가 매우 떨어질 수 있다.
그 외에도 더 있겠지만 이 글에선 위의 두 가지만 이야기하도록 하자.
물론 여러가지 해결법이 있다.
SPA의 단점 해결하기
크롤링 문제
정적 사이트 생성
- https://www.gatsbyjs.org 와 같은 정적 사이트 생성기를 이용하는 방법이다.
- 하나만 존재하던 index.html을 url 패턴에 대응하여 각 패턴마다 미리 생성해둔다고 생각하면 된다.
- 요새 이런 방식을 [https://jamstack.org/](JAM Stack) 이라고 하는 것 같다.
https://roto.dev 나 https://idios.band 를 이 방식으로 개발했었다.
정적 사이트 생성을 할 경우 서버 사이드 렌더링의 효과도 같이 누릴 수 있어서 열심히 머리를 굴려봤으나, 다음과 같은 이유들로 포기했다.
- 카테고리 별로 index.html을 생성해야 하고
- 프로그램 별로도 index.html을 생성해야 하면서
- 에피소드 별로도 생성해야한다.
- 거기에 지원 언어가 3개니까,
(카테고리 경우의 수 + 프로그램 경우의 수 + 에피소드 경우의 수) * 3만큼의 초기 index.html 생성이 필요하다. - 물론 위의 초기 생성 이후는 위의 데이터들이 어드민에서 변경될 때마다 해당 데이터에 속하는 페이지만 다시 빌드하여 업로드하는 등의 파이프라인을 만들면 되긴 하지만, 머릿 속에 이론만 있고 실제 구축해본 경험은 없어 포기하였다.
server side rendering 제공
server side rendering을 제공하는 방법이다.
이 경우 express 등을 통해 front-end를 제공해야하는데 위에서 이야기한 serverless의 잇점을 포기해야하고, 무엇보다 SSR를 하면서 생기는 복잡도 대비 이득이 적다고 생각해서 포기했다.
https://prerender.io/ 와 같은 서비스도 있는데 실제 사용해본 적은 없어서 도입을 고려해보진 않았다.
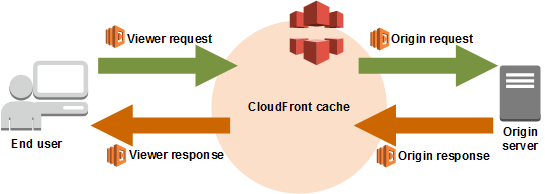
aws lambda edge
aws cloudfront를 사용하고 있다면 쓸 수 있는 방법이다. cloudfront에서는
- 요청이 들어왔을 때
- 요청이 오리진 서버로 도달했을 때
- 오리진 서버에서 응답을 줬을 때
- 최종 사용자에게 응답이 갈 때
의 네 가지 경우에 aws lambda 함수를 실행해서 응답을 변경할 수 있다.
그림으로 보면 아래와 같은 흐름이다.
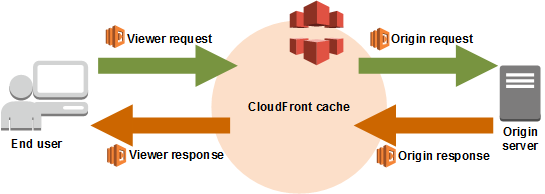
위의 개념을 이용해, index.html을 요청하는 시점에 meta tag를 갈아치우는 방법을 사용했다.
aws lambda edge를 이용해 구현하기
계획은 아래와 같다.
- meta tag 생성이 필요한 url 요청인 경우 cloudfront의 behavior에 추가한다.
- 특정 url 패턴인 경우의 캐시 정책을 다르게 정할 수 있고, lambda edge 함수를 실행하도록 설정할 수 있다.
- 해당 behavior의 origin response 타이밍에 특정 lambda 함수를 싱행하게 한다.
- 이 lambda 함수는 index.html을 s3에서 로드하여, 아래의 경우에 따라 meta tag를 만들고 이것을 응답으로 내보낸다.
- category url인 경우(/en/drama) 해당 카테고리의 데이터를 API에서 가져와 meta tag를 생성
- program url인 경우(/en/program/hello-world) url에서 program slug를 파싱해 API를 통해 데이터를 획득하고 meta tag를 생성
- episode url인 경우(/en/watch/hello-world/ep-1) url에서 episode 조회를 위해 필요한 정보들을 파싱한 후 API에서 데이터를 가져와 meta tag를 생성
위의 흐름을 간략하게 코드로 표현하면 이런 느낌이다.
/// handler 라는 이름의 함수를 export해야 aws lamda edge에서 쓸 수 있다. module.exports.handler = async (event, context, callback) => { // evnet의 Records 배열 0번의 cf에서 request, response를 꺼낼 수 있다. const { request, response } = event.Records[0].cf const { uri } = request const { language, programSlug } = parseProgramUri(uri)const program = await fetchProgram(programSlug) const { title, imageUrl, description, keywords } = extractMeta(program)
const html = async loadHTML() // index.html 불러오기
const replacedHTML = html .replace(/<title>(.)</title>/, ”) .replace( /<html lang=”(.)”><head><meta charset=“utf-8”/>/,
<html lang="${language}"><head><meta charset="utf-8" />${createSEOMeta({ title, imageUrl, description, url:${domain}${uri}, keywords, imageWidth, imageHeight, })}) // meta 태그 삽입
return callback(null, createResponse(replacedHTML)) // }
대충 어떤 느낌인지 오는가?
https://blog.roto.codes/create-react-app-using-firebase-functions/ 에서 사용한 방식과 동일한 방식이라고 보면 되겠다.
legacy url redirect 처리
meta og의 처리 외에도 요구사항 중에 옛날 url로 들어오면 바뀐 url로 redirect 시켜달라는 것이 있었다.
url redirect 규칙은 아래와 같았다.
- 카테고리 페이지
/{category-slug}- =>
/{language}/category/{category-slug}
- 프로그램 페이지
/{category-slug}/{program-slug}- =>
/{language}/program/{program-slug}
- 에피소드 페이지
/{category-slug}/{program-slug}/{episode-slug}- =>
/{language}/watch/{program-slug}/{kind}-{episodeNumber}
이 외에도 네다섯 페이지의 경우의 수가 더 있지만

redirect 처리하기
origin request (view request에서도 될진 모르겠다. 여기서 하는 게 맞는 것 같기도 하고)에서 redirect 해야하는 경우 아래와 같은 모양의 request json을 만들어서 callback에 넣으면 redirect 된다.
const redirectRequest = {
status: '301',
statusDescription: 'Moved Permanently',
headers: {
location: [
{
key: 'Location',
value: redirectUrl,
},
],
},
}
코드는 대략적으로 아래의 느낌이다.
const LegacyRedirectType = { PAGES: 'PAGES', BLOG: 'BLOG', SEARCH: 'SEARCH', CATEGORY: 'CATEGORY', PROGRAM: 'PROGRAM', EPISODE: 'EPISODE', ..... }// type별 핸들러 const redirectHandler = { [LegacyRedirectType.PAGES]: async(request, uri, querystring) => {…}, [LegacyRedirectType.BLOG]: async(request, uri, querystring) => {…}, [LegacyRedirectType.SEARCH]: async(request, uri, querystring) => {…}, [LegacyRedirectType.CATEGORY]: async(request, uri, querystring) => {…}, … }
module.exports.handler = async (event, context, callback) => { const { request } = event.Records[0].cf const { uri, querystring } = request
const legacyRedirectType = parseLegacyUrlType(uri, querystring)
// legacy redirect type이 아니라면 if (!legacyRedirectType) { // 가던 요청 마저 가십시오 return callback(null, request) }
return redirectHandler[legacyRedirectType](request, uri, querystring) }
쉽지 않았던 부분
이론 상으로는 단순명료했으나, 실제로 하면서 매우 많은 삽질을 했다.
디버깅의 어려움
aws에 대한 깊은 이해 없이 aws를 주먹구구식으로 필요할때만 찾아서 하다보니, 디버깅 하는데 어려움을 많이 겪었었다.
- aws lambda edge의 실행 결과는 aws cloudwatch에 남는다.
- cloudfront 요청을 처리한 리젼에 남는다.
- 즉 aws lambda는 버지니아 리젼에 있어도, 한국에서 테스트 할 경우 로그는 서울에 남는다는 것이다.
- 어떻게 보면 매우 당연한건데 이것 때문에 초반에는 로그를 못 찾아서 고생을 했다.
로컬 테스트의 어려움
aws lambda는 로컬 테스트를 어느정도 용이하게 할 수 있으나, aws lambda edge 같은 경우는 로컬에서 테스트하기가 쉽지 않았다.
aws lambda 같은 경우 express 같은 앱을 그냥 띄워서 한다고 생각하면 되는데, 위의 예제 코드에서 봤듯이 aws lambda edge를 로컬에서 테스트하려면 테스트 코드 내에서 event, context, callback 파라메터를 mock으로 만들어야 한다. 이게 케이스별로 어떤 형태로 들어가있는지 대한 문서를 찾기 힘들었다. 그래서 실제로 어떤 값이 들어있는지 보기 위해 console.log로 찍어보는 코드를 배포하고, cloudwatch에서 보고 확인하는 식의 처리를 하고야 말았다.
lambda console 상에서 테스트하는 방법도 있는 거 같았는데, 몇번 시도해보다 잘 안 되는 것 같아서 접었다. 이것은 실제 코드를 구현할 때 시간에 쫓기던 상황이었어서 좀 느긋하게 코딩할 수 있던 환경이면 테스트 방법까지 완벽하게 고려한 뒤 작업을 시작했을텐데 아쉬운 부분이다.
테스트 부분은 이렇게 해결했다.
- handler script는 최대한 간단하게 가져가고, 나머지는 Unit Test를 빡세게 해서 어느정도 해결을 했다.
- handler 쪽은 일반적인 서버 애플리케이션의 controller 역할만 하고, 나머지는 코드를 다 잘개 쪼개서 mocha로 Unit Test를 작성했다.
API 연동의 어려움
실제 meta tag 치환을 위해서는 카테고리, 프로그램, 에피소드 등의 API를 호출할 수 있었어야 했는데, API 같은 경우 production 환경에 배포된 것이 아니면 보통 내무망에서의 접근만 허용하므로 aws lambda edge에서 접근할 수가 없다.
물론 dev 기준으로 개발하고 실제 facebook og debugger나 twitter card validator 등을 돌리지 않고 단순히 생성된 html만 검증하는 방법도 있긴 했지만, 이렇게 해놔도 실제 facebook og debugger 등을 통해 볼 경우 의도대로 동작하지 않을 가능성이 있어서 prodution 환경이 모두 세팅되기 전까지 요 작업은 미뤄두고 다른 작업들을 하고 있었다.
그러다보니 프로젝트 막바지에 급하게 처리하게 되어서 결과적으로는 사소한 실수를 많이 하게 됐고, 시간낭비도 많이 했따.
cloudfront behavior url pattern 처리의 어려움
해당 url 패턴이 생각보다 기능이 빈약하다. 정규표현식을 지원하지 않고, wildcard만 지원을 한다.
초반에는 단순히 lambda edge 호출 횟수를 줄이기 위해 url 패턴별 behavior를 만들어서 처리하는 방식을 생각했다.
이렇게 하니까 legacy category url 처리하는 것만해도 behavior를 legacy category 갯수만큼 만들어야 했다.
/(drama|news|movie|variety|kis)와 같은 url pattern을 지원하지 않기 때문이다.- 그렇다고
/*로 처리하면....... 자세한 설명은 생략한다.
결국 default behavior를 제외하고 모든 behavior를 삭제하고, https://www.npmjs.com/package/url-pattern 와 같은 모듈을 통해 uri를 파싱하여 패턴에 따라 lambda를 실행하거나 무시하게 하는 등의 코드를 추가로 작성해야했다.
그외에
코드량도 적고 간단한 줄 알고 TypeScript를 안 붙이고 작업했다. 단순히 데이터 mocking 처리하고 작업했을 떄에는 코드가 간단했으나, url을 처리해야하는 경우의 수가 더욱 더 늘어났고 legacy url redirect까지 구현하다보니 코드는 더욱 더 복잡해졌다. 그리고 급하게 하다보니 배포를 한 후에야 변수명에서 오타를 냈거나, 파라메터 타입을 잘못 썼거나 하는 실수를 발견하기도 했다.
TypeScript나 lint 도구들을 붙였으면 이러한 삽질을 더 줄였을 것이다.
그리고 생각치도 못한 캐시 문제를 만났는데, aws lambda edge의 응답 결과는 url 기준으로 cloudfront에 의해 캐싱이 된다. 그렇다보니 응답이 캐싱된 상태에서 어드민에서 데이터를 변경해도 해당 캐시가 날아가기 전까지는 바뀌기 전의 내용으로 제공이 된다.
거기에 facebook og 자체의 캐시도 있고 해서 이 부분은 어떻게 처리해야하나 아직 고민중인 부분이다. 실제로는 이것 때문에 문제가 생길 케이스가 적을 것 같아서 그냥 운영팀에서 요청하면 엔지니어링 부서에서 직접 캐시를 날리는 액션을 취하는 방법으로 우선 할 것 같다.(cloudfront cache invalidate 및 facebook og debugger tool에서 캐시 날리기)
serverless
처음에는 작성한 코드를 긁어다가 aws lambda 코드 편집기에 붙여넣고 배포하는 식으로 했다가, 이 방법은 좀 아닌 거 같아 https://serverless.com/ 를 이용해 배포하는 방식을 썼다.
실제 구현
실제 코드는 위에 샘플 코드보다 훨씬 복잡해진다.
아래도 대략적인 예시 코드다.
const LambdaType = { CATEGORY: 'CATEGORY', PROGRAM: 'PROGRAM', EPISODE: 'EPISODE' }const handlers = { [LambdaType.CATEGORY] = async(req, res, callback) => {…}, [LambdaType.PROGRAM] = async(req, res, callback) => {…}, [LambdaType.EPISODE] = async(req, res, callback) => {…}, }
/// handler 라는 이름의 함수를 export해야 aws lamda edge에서 쓸 수 있다. module.exports.handler = async (event, context, callback) => { // evnet의 Records 배열 0번의 cf에서 request, response를 꺼낼 수 있다. const { request, response } = event.Records[0].cf const { uri } = request
// lambda를 실행해야하는 url인지 파싱한다. const lambdaType = parseLambdaType(uri)
// lambda를 실행할 타입이 아니면 그냥 by pass if (!lambdaType) { // 이 경우 생성되어있는 response를 callback에 넘기면 된다. return callback(null, response) }
return handler[programType](request, response, callback) }
구현 후 느낀점
aws lambda edge를 이용해 구현하면서 느낀점들이다. 우여곡절을 많이 겪기는 했으나 생각보다 잘 돌아가고 있는 것 같아 뿌듯하다.
TypeScript, lint 등의 도구를 잘 붙이고 작업하자.
배포 전에 코드 레벨에서 검증할 수 있는 것은 최대한 검증하도록 하자.
Unit Test를 탄탄하게 작성해두자.
이 험난한 클라우드 세상 속에서 믿을 건 Unit Test 뿐이다.
url parsing은 직접 하자.
정규표현식 잘 짜는 사람들 부럽다.
serverless 등의 도구를 이용해 배포를 관리하자.
추가로 구현하고 싶은 것
redux 연동
aws lambda edge에 의해 캐싱이 되긴 하지만, 결과적으로는 meta og tag 구성을 위해 API를 호출하고 실제로 client side에서 렌더링 되면서 API를 한번 더 호출하게 된다.
만약 redux가 있는 상태였다면 meta og tag를 구성하는 김에 SSR에서 하듯이 초기 state를 구성해놓고 가져다 쓰는 식으로 바꾼다면 client side에서 API 요청하는 횟수 한번을 줄일 수 있을 것 같다.
지금은 redux를 프로토타이핑 때엔 넣었으나 뺸 상태로, 다시 넣을 예정이다. 넣게 되면 aws lambda edge로 SSR까지 커버할 수 있을지 연구를 좀 더 해봐야겠다.
테스트 도구 만들기
그리고 facebook og debugger로 매번 테스트하는 대신, curl 등으로 html을 가져오고 생성된 html을 검증하는 등의 테스트 도구도 만들어두면 앞으로의 유지보수를 좀 더 편하게 할 수 있을 것 같다.
거대해지는 번들 해결 해결하기
이건 페이지 단위로 번들을 쪼개는 것으로 쉽게 해결했다. 그냥 아래처럼 하면 된다.
// 기존 import문. 이 경우 기본 번들에 포함되어서 용량이 커지고 스크립트 번들이 커진다. import HomePage from './pages/home/HomePage'
// lazy 이용 const HomePage = lazy(() => import(‘./pages/home/HomePage’))
이렇게 lazy를 이용한 즉시실행 함수 형태로 처리하면, 빌드 시 lazy 선언된 코드는 분리가 되고 실제 필요한 순간에 로딩된다. create-react-app을 사용하는 경우 별도의 설정 없이 저렇게 코드를 작성하는 것만으로도 번들 분리가 되니 정말 편하고 좋은 세상이다.
관련해선 한글 문서도 있으니 https://ko.reactjs.org/docs/code-splitting.html 를 참고하도록 하자.
마치며
aws lambda edge는 대략적인 흐름 정도만 이해하고 있던 상태고 실제 프로젝트에 적용해본 건 이번이 처음이다. 기초지식 부족으로 초반에 삽질을 많이 겪기는 했지만, 그래도 serverless 형태를 유지하면서 서버 관련 요구사항을 모두 만족시킨 것 같아 만족스럽다.
이제 지옥의 리팩토링과 테스트 코드 보완, 그리고 zone 나누기 작업이 남았다. 지금은 production용 cloudfront에서만 동작하고 있어서 유지보수를 생각하면 dev, staging 정도 까지는 나눠서 테스트 할 수 있도록 해야 할 것 같다.
그리고 지금은 serverless 도구를 통해 배포를 하고 있으나, 실제 cloudfront에 연결하는 작업은 수동으로 하고 있다. 이 부분을 어떻게 자동화 할지는 SRE팀과 논의를 좀 더 해봐야 할 것 같다.